
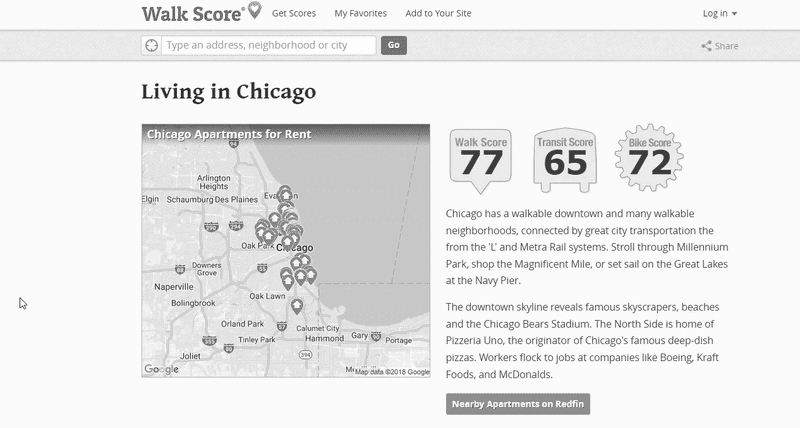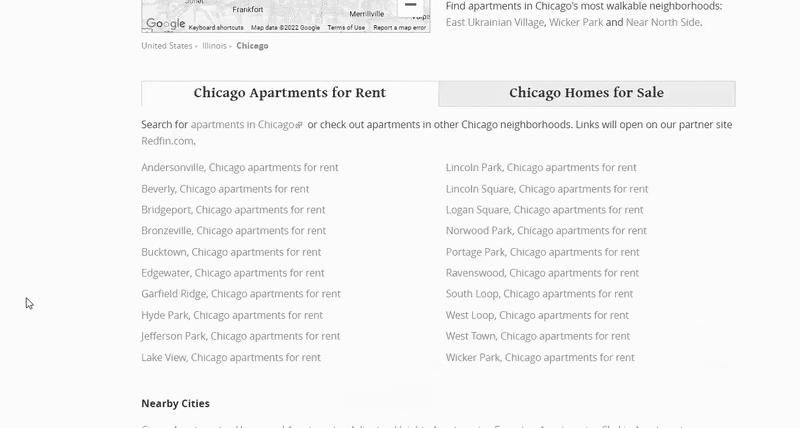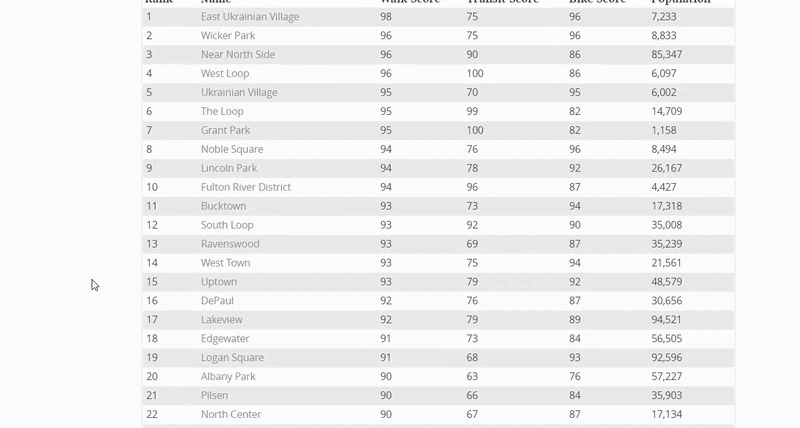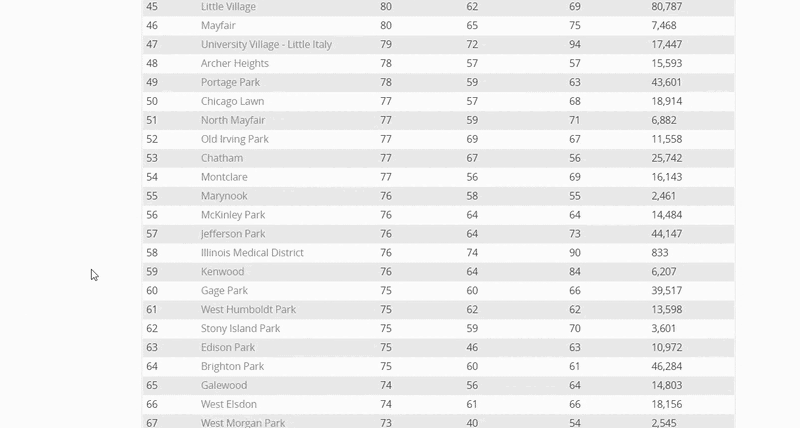
1.
Road Maps
Image classification with Keras to identify correlation between visual street network & Walk Scores
Kit Nga Chou | Kirthi Balakrishnan | Michelle Chen | Lizzie Lee


Image classification with Keras to identify correlation between visual street network & Walk Scores

Neighborhood-wise bus stop location identification & occurance calculations

Extracting intersection nodes from openstreetmap plots & calculating densities for each neighborhood

















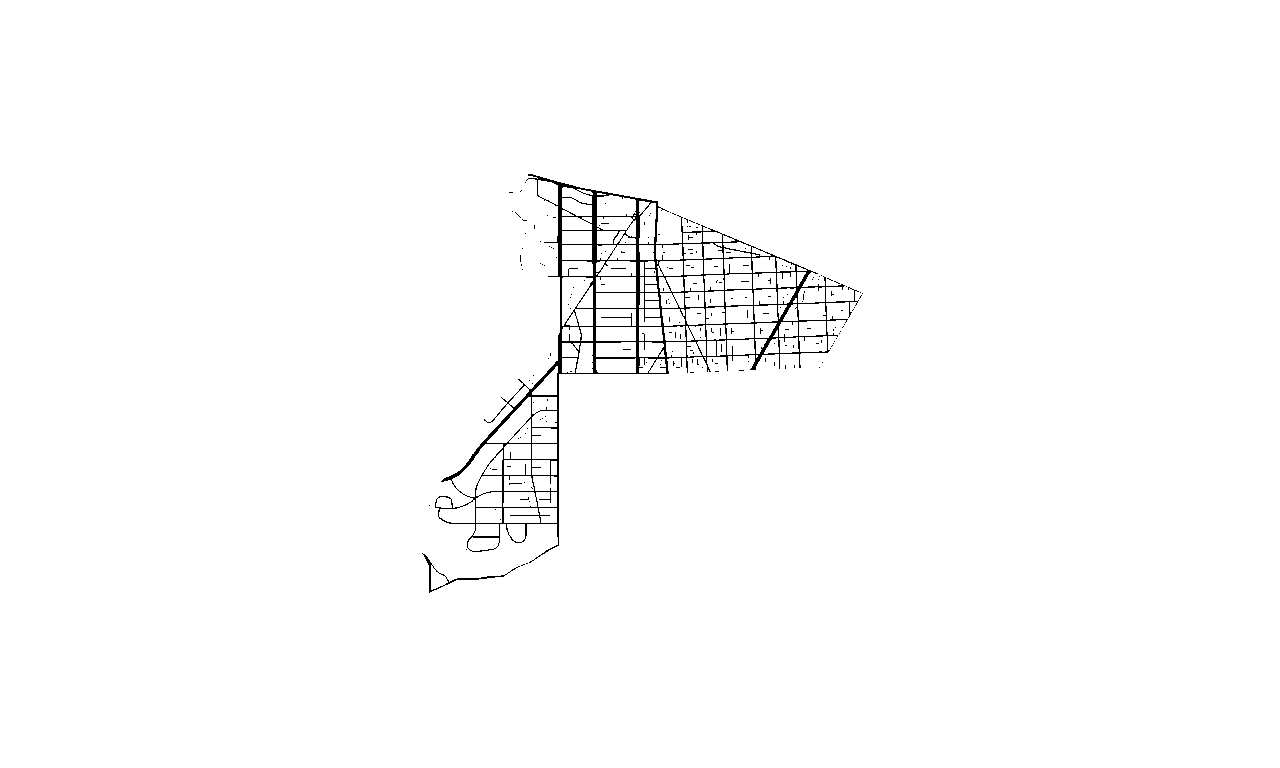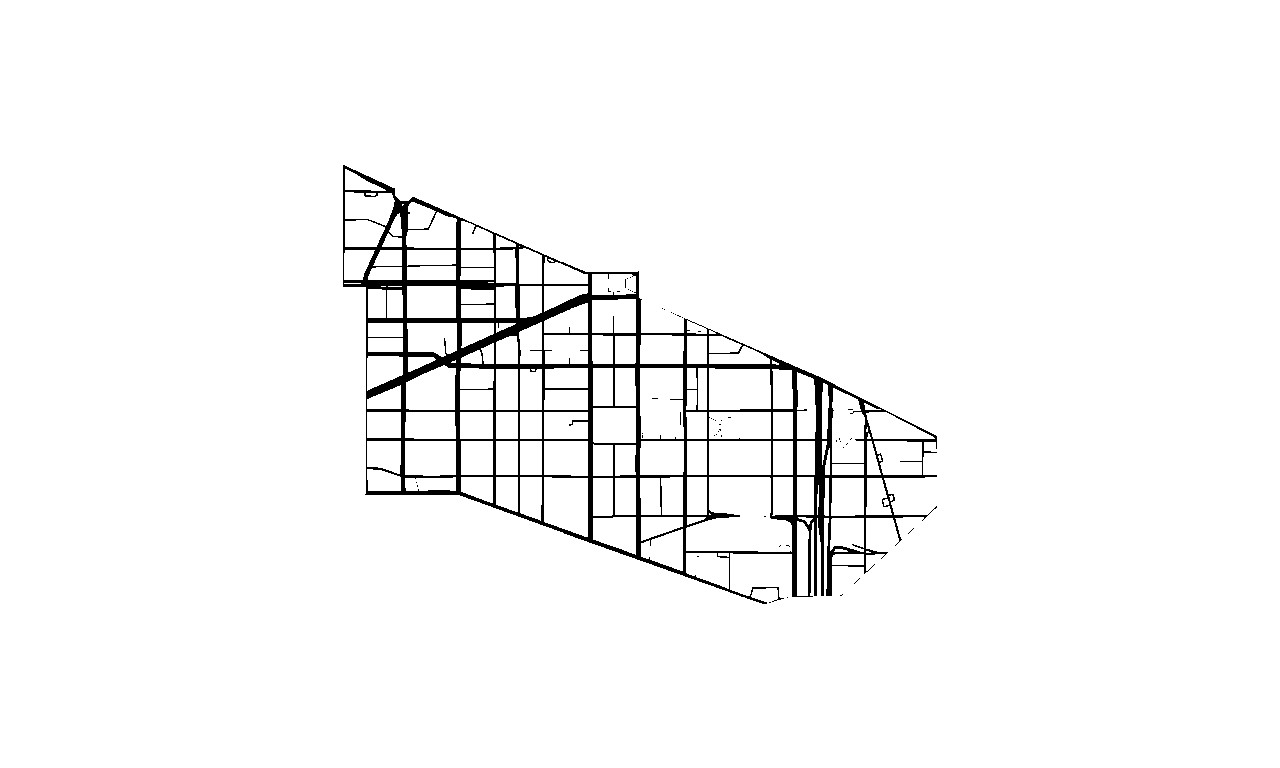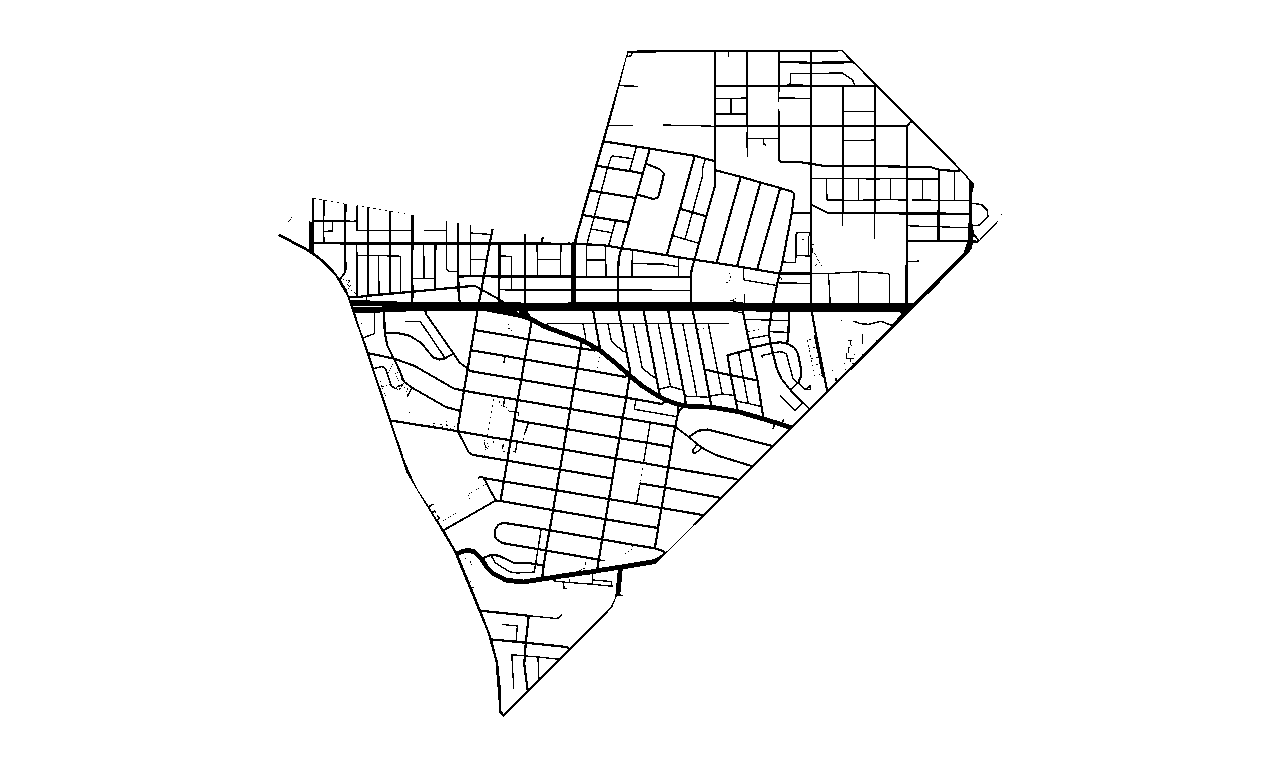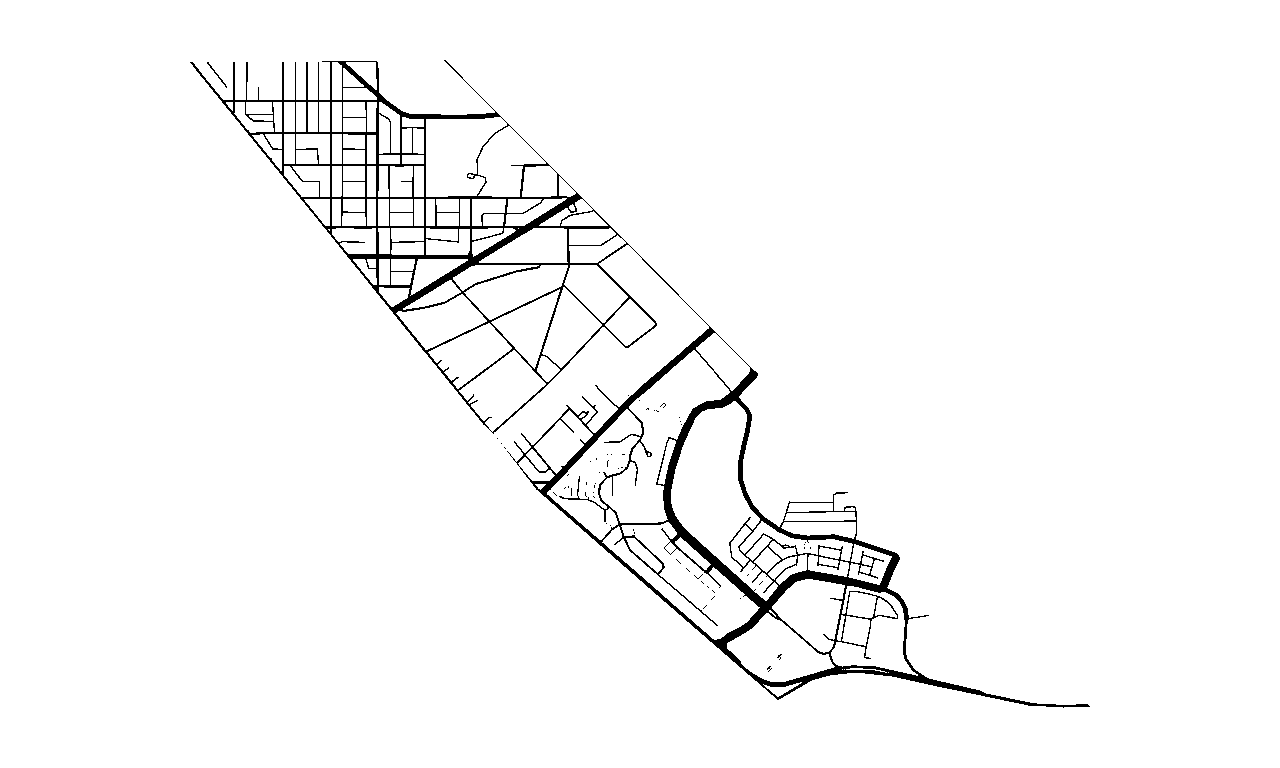

Unprocessed Image
Training accuracy increases
Validation accuracy is fickle

Unprocessed Image
Training loss decreases
Validation loss is fickle

Processed Image
Training accuracy increases
Validation accuracy is stagnant

Processed Image
Training loss decreases
Validation loss increases

Use Overpass Turbo wizard to generate query

Use Overpass API to extract points to Python

Use bounding box + count to find number of bus stops

By area & population/1000 of the neighborhood























